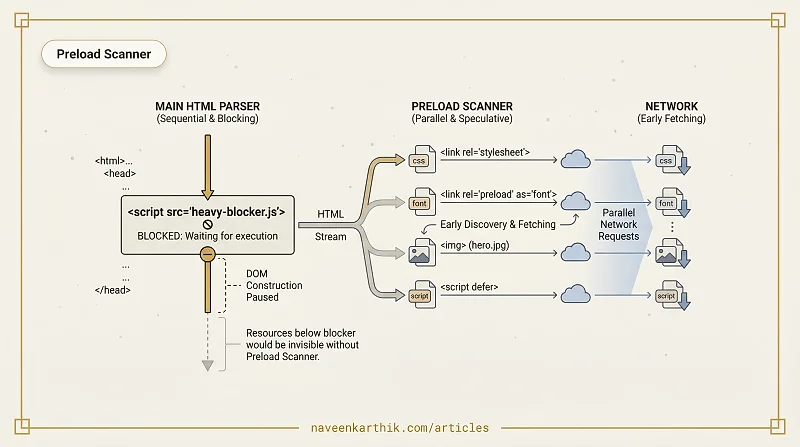
The preload scanner is a secondary HTML parser that the browser runs in parallel with the main parser. Its only job is to look ahead in the HTML stream and discover resources — scripts, stylesheets, images, fonts — so their network requests can be dispatched as early as possible, even while the main parser is blocked.
Why it exists
The main HTML parser builds the DOM incrementally. When it encounters a blocking resource — a <script> without async or defer, or a <link rel="stylesheet"> — it stops and waits for that resource to download and process before continuing.
Without a preload scanner, every subsequent resource in the HTML would be invisible until the blocking resource finished. A slow script in <head> would delay the discovery of every image, font, and stylesheet below it.
The preload scanner solves this by scanning ahead through the raw HTML bytes, finding src= and href= attributes, and dispatching fetch requests — without waiting for the main parser to catch up.
What the preload scanner can and cannot find
Can discover:
<script src="...">— even while waiting for a blocking script<link rel="stylesheet" href="..."><img src="...">and<img srcset="..."><link rel="preload" as="..."><video poster="...">
Cannot discover:
- Resources injected by JavaScript (
document.createElement('script')) - Resources referenced only in CSS (
background-image: url(...)) - Resources loaded conditionally by JavaScript at runtime
- Resources behind
import()calls
Why this matters for performance
The preload scanner is why resources that appear below a blocking script in the HTML often still start downloading early. Without it, the critical path would be strictly serial — every resource waiting for the previous one.
It also explains a common performance gotcha: if a critical resource can only be discovered by JavaScript (a dynamically built image URL, a font loaded via a CSS-in-JS library), the preload scanner won't find it. The resource stays hidden until JS runs.
The fix is explicit <link rel="preload"> hints in the HTML:
The preload scanner and defer/async
Scripts marked defer or async are still discovered by the preload scanner and fetched in parallel with HTML parsing — they just don't block the parser when they execute. This is a key part of why defer improves page load: the script download happens speculatively while parsing continues.
The preload scanner is invisible but essential. It's the reason modern pages can load multiple resources in parallel despite the single-threaded nature of HTML parsing. When a resource loads later than expected, checking whether the preload scanner can see it is always the right first question.