Parsing is the process of reading raw text — HTML, CSS, or JavaScript — and converting it into a structured, in-memory representation the browser can work with. It's the very first thing the browser does after downloading a resource, and nothing else can happen until it's done.
In the context of the browser rendering pipeline, parsing covers the first two steps: turning HTML into the DOM, and turning CSS into the CSSOM.
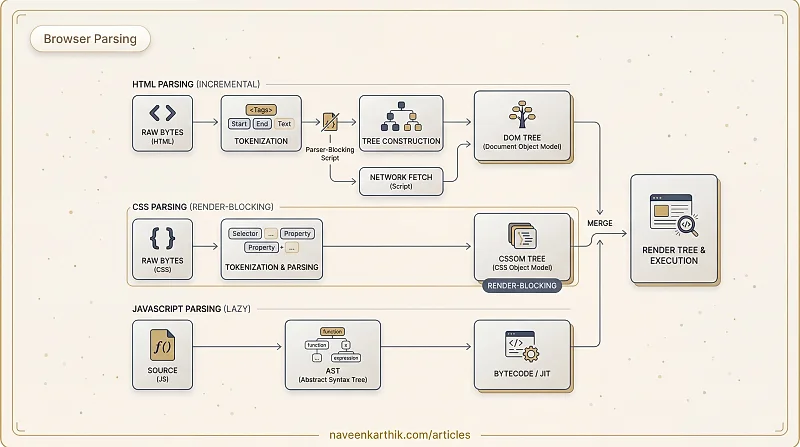
HTML Parsing → DOM
When the browser receives HTML bytes from the network, its HTML parser processes them through two stages:
- Tokenization — the raw character stream is broken into tokens: start tags, end tags, attribute names and values, text content, and comments.
- Tree construction — those tokens are assembled into a tree of node objects — the DOM.
HTML bytes → Characters → Tokens → Nodes → DOM Tree
Parsing is incremental: the browser doesn't wait for the entire HTML document to arrive before it starts building the tree. It processes the stream as it comes in and emits nodes along the way. This is why you can see content appearing on screen before the full page has loaded.
Parser-Blocking Scripts
When the HTML parser encounters a <script> tag (without async or defer), it stops parsing entirely:
- Fetches the script (if external)
- Waits for all preceding CSS to finish parsing (scripts may read computed styles)
- Executes the script
- Resumes parsing
This is called parser blocking. A single slow script in the <head> can delay the entire page because the browser can't build the DOM past that point.
defer and async exist specifically to break this blocking behaviour — they allow the parser to continue building the DOM while the script downloads.
The Preload Scanner
While the main parser is blocked by a script, a secondary parser called the preload scanner runs ahead through the remaining HTML looking for resources to fetch — images, stylesheets, scripts. It dispatches network requests early so the browser doesn't sit idle waiting for the blocking script to finish.
CSS Parsing → CSSOM
CSS parsing works differently from HTML parsing. When the browser encounters a <link rel="stylesheet"> or a <style> block, it:
- Downloads the stylesheet (if external)
- Tokenizes the CSS text into selectors, properties, and values
- Resolves specificity, inheritance, and cascade
- Builds the CSSOM — a tree of fully computed styles
CSS parsing is render-blocking — the browser won't produce any pixels until the CSSOM is fully built. Without complete style information, the browser would render unstyled content and then immediately re-render once styles arrive, which is worse than waiting.
CSS does not block HTML parsing, though. The DOM can keep building while stylesheets download and parse. What CSS blocks is the merge step — the browser can't build the Render Tree until both the DOM and CSSOM are ready.
JavaScript Parsing
JavaScript also goes through a parsing phase before it runs. The JS engine (like V8) parses the script source into an Abstract Syntax Tree (AST), then either interprets it or compiles it to bytecode/machine code via JIT compilation.
V8 uses lazy parsing — it fully parses only functions that are immediately invoked and does a quick "pre-parse" of the rest. This reduces startup time because not all code is needed immediately.
Why Parsing Matters for Performance
Parsing is the gateway to everything else. No DOM means no render tree, no layout, no paint, no pixels. Every millisecond spent blocked or waiting during parsing is a millisecond added to First Contentful Paint and Time to First Byte response time.
The Critical Rendering Path is essentially the sequence of parsing and rendering steps the browser must complete before it can show anything. Shortening it means:
- Fewer render-blocking stylesheets — inline critical CSS, async-load the rest
- No parser-blocking scripts — use
deferorasyncon every<script> - Smaller documents — less HTML and CSS means less to parse
Parsing is the foundation. Rendering — what happens after parsing — can't begin until the parser has done its job.